 Thambaru Wijesekara
Thambaru Wijesekaraඉස්සර වචන පේළියක තේරුම හොයාගන්නට අවශ්ය වුණාම වචනයෙන් වචනයට ගල්පොත සෙල්ලිපිය තරම් බර ඩික්ෂනරිය පෙරළන්නටත්, පසුකාලීනව ඩික්ෂනරි ඇප් එකේ එකින් එක ටයිප් කරලා තේරුම සොයාගන්නටත් සිදු වුණාට, Google Translator එක සිංහල බසට පැමිණියාට පස්සේ ඉතාම පහසුවෙන් වචන පේළියම පේස්ට් කරලා එහි තේරුම බලාගන්නට හැකියාව ලැබුණා. හැබැයි පේළි ගණන වැඩි වෙද්දි නිරවද්යතාව තවමත් අඩු මට්ටමේ පැවතුණත් ගූග්ල් සමාගම සිංහල බස පිළිබඳව අවධානය යොමු කිරීම හරහා අනෙකුත් වෙබ් අඩවි වලටත් සිංහල ගැන සිතන්නට පෙළඹවීමත්, සහ පරිගණක සාක්ෂරතාව වෙනුවෙන් එය අපේ රටට විශාල කාර්යයභාරයක් ඉටු කරන බව සිහි කිරීමෙන් ඇඟ කිළිපොළා යන තරම් සතුටක් විඳින්නට පුළුවන්.
ඒත් මේ යාන්ත්රික පරිවර්තනයන් සිදුවන්නේ කොහොමද? පරිගණකයක් අපි තරම්ම සිංහල භාෂාව තරම් සංකීර්ණ බසක් හසුරුවන්නේ කොහොමද? මේ ලිපිය කුතුහලයෙන් පිරි ඔබ වෙනුවෙන්.
1950 කාලයේත් තිබුණු භාෂා පරිවර්තන යන්ත්ර

යාන්ත්රික පරිවර්තකයක ප්රථම ප්රසිද්ධ හඳුන්වාදීම නිව්යෝර්ක්හි IBM ප්රධාන කාර්යාලයේදී සිදුවූ අවස්ථාව (Wikipedia, IBM Archives)
භාෂා පරිවර්තනය යන්ත්රයකට පැවරීමේ සිහිනය 1954දී සැබෑවක් බවට පත් වුණේ ඇමරිකාවේ ජෝර්ජ්ටවුන් සරසවිය IBM ආයතනය හා එක්ව රුසියානු බස ඉංග්රීසියට පරිවර්තනය කරන යන්ත්රයක් සැකසීමත් සමඟයි. 1953දී එළිදැක්වූ IBM 701 mainframe පරිගණකයකින් සිදු කෙරුණු මේ Georgetown අත්හදාබැලීමෙහි පරිවර්තන සඳහා වාක්ය ලබා දිය යුතුවූයේ Punch Card ක්රමය (පත්රයක සිදුරු විද එය පරිගණකයට Input කරන ක්රමවේදයක්) හරහා යි. මේ යන්ත්රයේ ශබ්දමාලාවේ කොටස් 250ක් පමණ සහ ව්යාකරණ නීති 6ක් ඇතුලත්ව තිබුණා. කාබනික රසායනික විෂයය අරමුණු කරගත් මෙහි තාක්ෂණය පූර්ණ වශයෙන් පිටතට ලබා දුන්නේත් නැහැ. මෙය නිපැයීමෙන් ඉතා විශාල ධනායෝජනයන් ද මෙම ව්යාපෘතියට ලැබුණේ ඔවුන් වසර 3 සිට 5ක කාලයක් තුළදී සර්ව සම්පූර්ණ යාන්ත්රණයක් සකසන බවට විශ්වාස කළ නිසායි. මීට පෙර ද 1930 මැද භාගයේ දී එස්පෙරෙන්තෝ භාෂාව මුල් කරගත් යන්ත්රයකට Georges Artsrouni නමැත්තෙක් විසින් පේට්න්ට් බලපත අයැදුම් කර තිබුණා.
යාන්ත්රික පරිවර්තනයන්ට විනෝදාත්මක ප්රතිචාර
Frozen චිත්රපට ගීතය භාෂා කීපයක් හරහා පරිවර්තනය කොට නැවත ඉංග්රීසි බසින් ගැයෙන වීඩියෝවක්
1990 පමණ වෙද්දී Text to Speech හෙවත්, දෙන ලද වාක්ය ඛණ්ඩයක් ශබ්ද නගා කියවීමේ තාක්ෂණය හොඳින් කලඑළි බැස තිබූ අතර භාෂා සඳහා පරිගණක භාවිතය අපූර්ව ප්රවෘත්තියක් බවට පත්ව තිබෙන්නට ඇති. යන්ත්ර විසින් තම රැකියාව ප්රතිස්ථාපනය කරනු ඇතැයි යන බිය තවමත් තාක්ෂණයේ උන්නතියත් සමඟ හැම කෙනෙක්ටම ඇති වෙනවා. නමුත් මේ යාන්ත්රික පරිවර්තන විසින් පරිවර්තකයෙකුගේ රැකියාව අහිමි කරනු ඇතැයි යන බියටත් වඩා, එම යාන්ත්රික පරිවර්තන, විශේෂයෙන් ලොව පතල Google Translator එකෙන් පරිපූර්ණ ප්රතිදානයක් නොලැබෙන නිසා ඉන් විහිළු පවා ගොඩනැගුණා. ලංකාවෙන් #OddSinhalaTranslations ලෙස ට්විටරයේත්, කිසියම් ගීතයක් භාෂා කීපයකට පරිවර්තනය කොට නැවත ඉංග්රීසි බසට පරිවර්තනය කොට ගයන ලද වීඩියෝ යූටියුබ්හිත් දකින්නට ලැබුණේ සමාජ ජාලවලට විනෝදය ගෙන එන නවමු මඟක් එළි පෙහෙළි කරමින්.
සංඛ්යාලේඛන මත යැපෙන Google පරිවර්තකය

විවිධ ආදානයන්ගෙන් උගෙන ගූග්ල් පරිවර්තකය වාක්ය ගොඩනගන ආකාරය දක්වන චිත්ර සටහනක් (YouTube)
භාෂා ඥාණයෙන් යුත් අය ලවා පරිගණකයට ලොව විශාල සංඛ්යාවක භාෂා සහ ඒවායේ දහස් ගණන් නීති උගන්වනවාට වඩා ස්වයංක්රීයව දැනටම පරිවර්තනය කොට ඇති ලේඛන අන්තර්ජාලයෙන් සොයාගෙන තනිවම බස උගනින්නට හැකියාව ලබාදීම Google translatorහි ශීඝ්ර දියුණුවට හේතු වුණා. මෙතෙක් පැවති ක්රමයට වඩා මෙම සංඛ්යාන දත්ත (statistical data) ක්රමවේදය යන්ත්රවල භාවිතයේදී ගූග්ල් සමාගමට නම් පහසුවක් වූයේ එහි සෙවුම් යන්ත්රය හරහා ඒ වන විටත් අන්තර්ජාලය පුරා ඇති වෙබ් පිටු සහ ගොනු පිරික්සමින් සිටි නිසා වන්නට ඇති.
2016ට පෙර Deep Learning ක්රමවේදයත්, ඉන් පසු GNMT (Google Neural Machine Translation) ක්රමවේදයත් භාවිත කළ ගූග්ල් සමාගම දැන් වැඩිදියුණු කරන ලද RNN (Recurrent Neural Networks) පද්ධතිය සමාන ආකාරයේ වචන සහ වාක්ය හඳුනාගැනීමට භාවිත වෙනවා.
මෙම පරිවර්තනවල සත්යතාවය සහ විශ්වාසවන්තභාවය පවත්වාගන්නට ඔවුන් මූලික වශයෙන්ම එක්සත් ජාතීන්ගේ සංවිධානය විසින් ඔවුන්ගේ සාමාජික රටවල් සඳහා පරිවර්තනය කොට නිකුත් කරන ගොනු උපයෝගී කරගනිමින් මුල් පරිවර්තනය සමඟ ගලපමින් වාක්ය රටාවන් අධ්යයනය කොට හඳුනාගන්නට මෙම පද්ධතියට හැකියාව තිබෙනවා. ඊට අමතරව පරිශීලකයන්ට ද ස්වේච්ඡා දායකත්වයන් ලබා දී විශ්වාසවන්ත ලෙස හඳුනාගත් ඉහළ මට්ටමේ පරිශීලකයන් ලවා ස්ථිර කරවාගත හැකියි.
පරිවර්තනවල අජීවී බව

semantix.eu
සංඛ්යාන මත පදනම් වූ පරිවර්තන ක්රමයේදී වඩාත් සුදුසු පරිවර්තනයට වඩා වඩාත් ‘විය හැකි’ වචන යොදා වාක්යය සැකසීමයි සිදුවන්නේ. මෙහිදී වාක්යයකට ලැබිය යුතු ලස්සන වෙනුවට අජීවී ස්වභාවයෙන් යුත් ප්රතිදානයක් බොහෝ අවස්ථාවල දී දකින්නට ලැබෙනවා. කුඩා සරල වැකි පරිවර්තනය කිරීමේදී Google translator සමත් වූවත්, කොටස් කිහිපයකින් සමන්විත වාක්යයක් තනි පේළියකින් කී විට එය නිසිලෙස පරිවර්තනය කරන්නට එයට තවමත් අපහසුයි.
පහතින් අපි මූලාශ්ර වාක්යයක් ඉංග්රීසියෙන් සහ මනුෂ්ය පරිවර්තනයත්, යාන්ත්රික පරිවර්තනයත් අඩංගු කරනවා. හැකිනම් ඉන් යාන්ත්රික පරිවර්තනය හඳුනාගෙන කමෙන්ට් කරන්න.
ඉංග්රීසි වාක්යය
Roar.lk was awarded on many events including Social Media day in 2017.
පරිවර්තනය 1
Roar.lk වෙබ් අඩවියට 2017 වසරේදී සමාජ මාධ්ය දින සම්මානය ඇතුළු සම්මාන රැසක් හිමිවිය.
පරිවර්තනය 2
2017 දී සමාජ මාධ්ය දිනය ඇතුළු Roar.lk වෙබ් අඩවියට ප්රදානය කරන ලදී.
නිසි පරිවර්තනයක් ගොඩනැගෙන හැටි
Thambaru/Roar
එසේම මූලාශ්ර වාක්යය ඉංග්රීසි බස වන තරමට සාපේක්ෂ වශයෙන් ප්රතිදානයේ ඇති සාර්ථක බව ඉහළ අගයක් වෙනවා. එනම්, අන් භාෂා දෙකක් අතර ඇතිවන පරිවර්තනයකට පද්ධතිය සතු දත්ත ප්රමාණවත් නොවන නිසා ඊට වැඩි සාර්ථකත්වයක් ලැබෙන්නේ නැහැ. භාෂාවන් නීති පද්ධතියක් මත ගොඩනැගී තනි වචනයකින් තේරුම් රැසක් අරුත් ගන්වන නිසා එම සංකීර්ණ බව හමුවේ යන්ත්ර ක්රියා කරන්නේ අපහසුවෙන්. විශේෂයෙන් ඉංග්රීසි බස වැනි සරල භාෂාවක් මූලික කොටගෙන ක්රියාත්මක වන නිසා රෝමානු, ආසියාතික සංකීර්ණ භාෂාවන්ගේ සංකීර්ණ බව හඳුනාගන්නට එයට ඇති ඉඩකඩ බොහොම අඩුයි.
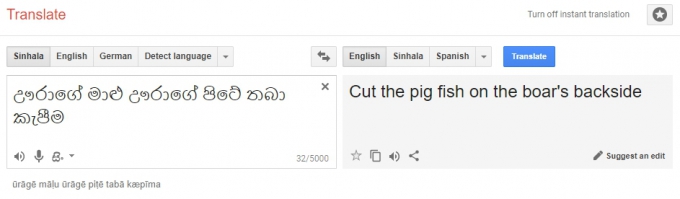
පරිවර්තනයක් කිරීමේ දී වචනයෙන් වචනයට රළු පරිවර්තනයක් කරනවා වෙනුවට, ප්රථමයෙන් සමස්ත අර්ථය සලකා බලා ඉන්පසු එය කියවන්නාට වඩාත් පහසුවන ආකාරයට, සහ කියවන්නාගේ ස්වභාවය සලකා බලා, උපමා රූපකවලට හානි නොකොට, සහ ඒවා භාෂාවට ගැලපෙන ලෙස වෙනස් කොට, සාහිත්යමය රසය ද රැකගෙන ව්යාකාරණානුකූලව පද පෙළ ගස්වා සරලව ඉදිරිපත් කළ යුතුයි. “ඌරාගේ මාළු ඌරාගේ පිටේ තබා කැපීම” ගූග්ල් ට්රාන්ස්ලේටරය දකින්නේ “Cut the pig fish on the boar’s backside” ලෙසයි. ඌරාගේ මාළු ලෙස අප ඌරු මස් අදහස් කළත් එය ඍජුව පරිවර්තනය කළාම Fish හෙවත් මත්ස්යයෙක් බවට පත් වෙනවා.
නමුත් මූලික වශයෙන්ම සංඛ්යාන දත්ත මත පදනම් නොවී පරීශීලක දායකත්වයන් ද මගින් ද ඉගෙන ගන්නා නිසා Google Translator එකට දිගු දුරක් ගමන් කළ හැකැයි යන විශ්වාසය ඇති වෙනවා. එය භාවිත කරද්දී පරිවර්තිත වාක්යය ඇති කොටුවේ දකුණු පස යට ඇති පැන්සල් අයිකනය මත ක්ලික් කොට වරදක් ඇතොත් නිවැරදි පරිවර්තනය ලබා දී දායක වන්නට ඔබටත් පුළුවන්.
[1] “IBM Archives: IBM 701.” https://www-03.ibm.com/ibm/history/exhibits/701/701_intro.html. Accessed 31 Jan. 2018.
[2] “The Georgetown-IBM experiment demonstrated in … – John Hutchins.” http://www.hutchinsweb.me.uk/AMTA-2004.pdf. Accessed 31 Jan. 2018.
[3] “Two precursors of machine translation: Artsrouni and … – John Hutchins.” http://www.hutchinsweb.me.uk/IJT-2004.pdf. Accessed 31 Jan. 2018.
[4] “Multilingual Text-to-Speech Synthesis – The Bell Labs Approach ….” http://www.springer.com/us/book/9780792380276. Accessed 31 Jan. 2018.
[5] “Statistical Vs Rule Based Machine Translation – arXiv.” https://arxiv.org/pdf/1708.04559. Accessed 31 Jan. 2018.
[6] “How does Google translate work? Do they have database for all ….” 13 Mar. 2015, https://www.quora.com/How-does-Google-translate-work-Do-they-have-database-for-all-words-of-a-particular-language. Accessed 31 Jan. 2018.
කවරයේ ඡායාරූපය: thewpcourse.com





.jpg?w=600)

