Kaniz Fatema Koly
Kaniz Fatema Koly
র্যাবের সাথে বা পুলিশের সাথে অভিযানে যেতে দেখা যায় সুঠাম দেহগঠনের আরেকটি বাহিনী, তাদের নাম ডগ স্কোয়াড। গুরুত্বপূর্ণ অভিযানে তাদের দক্ষতা এবং পারফরমেন্স প্রশংসার দাবিদার। তবে এক্ষেত্রে তাদেরকে দক্ষ করে যারা গড়ে তোলেন, তাদেরকে ভুলে গেলে চলবে না। কুকুরকে আর্মি ট্রেনিংয়ের মতো বিভিন্ন চ্যালেঞ্জিং ট্রেনিং দেয়া হয়, সেটা সকলেরই কম-বেশি জানা আছে। কিন্তু এক্ষেত্রে যে মনোবিজ্ঞানের থিওরিগুলোকে ব্যবহার করা হয়, তা হয়তো অনেকেরই অজানা। চলুন জেনে নেয়া যাক কীভাবে ডগ স্কোয়াড ট্রেনিংয়ে মনোবিজ্ঞানের থিওরি ব্যবহৃত হয়।

ঢাকা মেট্রোপলিটন পুলিশ ডগ স্কোয়াড; source: Dhaka Tribune
সাধারণ নির্বাচন প্রক্রিয়া
ডগ স্কোয়াডের কাজ মূলত গন্ধ শুঁকে বোমা বা মাদকদ্রব্য শনাক্ত করা। জন্মগতভাবেই এ ক্ষমতা সব কুকুরের মধ্যে থাকে। তারপরও বিশেষ কয়েকটি জাতের কুকুরের মাঝে এ ক্ষমতা প্রবল; যেমন- ল্যাব্রাডোর, ব্লাডহাউন্ড বা জার্মান শেপার্ড। একদম ছানা অবস্থায় সুস্থ দেখে কয়েকটি কুকুর নির্বাচন করে পাঁচ থেকে ছয় মাস বয়স পর্যন্ত মনিটর করা হয়। তারপর শুরু হয় ট্রেনিং। আর হ্যাঁ, মনিটরের সময়েই বাধ্য হতে শেখানো, টয়লেট ট্রেনিং ইত্যাদি টুকটাক শিক্ষাদান চলতে থাকে। যেহেতু সামরিক অভিযানে অংশগ্রহণ করবে, তাই প্রথমেই বিকট শব্দের সাথে মানিয়ে নেয়া শেখানো হয়। প্রথমে শব্দের মাত্রা কম থাকবে এবং ধীরে ধীরে বাড়াতে হবে এবং শেষে সত্যিকারের গুলির শব্দের সাথে মানিয়ে নেয়া শেখানো হয়। মোটামুটি এ ট্রেনিংগুলো শেষ হবার পর যে কুকুর ছানাগুলোর পারফরমেন্স ভালো থাকে, তারা ডগ স্কোয়াডে অংশগ্রহণের জন্য নির্বাচিত হয়।

ছানা অবস্থায় নির্দিষ্ট জাতের কুকুর এনে সেগুলোকে মনিটরিং করা হয়; source: Daily mail
এরপর থেকে প্রতিদিন কিছু লুকোচুরি খেলা খেলতে হবে তাদের সাথে। মানুষের ছোঁয়া জিনিস গন্ধ শুঁকে খুঁজে বের করতে হবে। পরবর্তী ধাপে যে মানুষের ছোঁয়া জিনিস খুঁজে পেয়েছে, সে মানুষটাকেই খুঁজে বের করা লাগে। এ ট্রেনিংয়ের সময় কুকুরের মুখে মুখবন্ধ দিয়ে নেয়া ভালো, কেননা অনেক সময় এরা আক্রমণাত্মক হয়ে পড়ে।

স্কোয়াড ডগ ট্রেনিংয়ের মুহূর্তে; source: You Tube
মনোবৈজ্ঞানিক থিওরি এবং স্কোয়াড ট্রেনিং
কুকুরকে ট্রেনিং দেবার প্রধান উদ্দেশ্যই হলো আচরণের পরিবর্তন আনা। আচরণে পরিবর্তন আনতে মানুষের ক্ষেত্রে ব্যবহৃত মনোবিজ্ঞানের থিওরিগুলোই কাজে লাগানো হয়। যেমন-
প্যাভলভের ক্লাসিক্যাল শর্তারোপ থিওরি
মনোবিজ্ঞানে আচরণ পরিবর্তনে ব্যবহৃত অন্যতম থিওরিগুলোর একটি হলো এই থিওরি। স্বাভাবিক একটি আচরণকে অন্য কিছু দ্বারা পরিবর্তন করাই এই থিওরির উদ্দেশ্য। প্যাভলভ এই থিওরিটি কুকুরের উপর প্রয়োগ করেই দিয়েছিলেন।
মাংস দেখলে স্বাভাবিকভাবেই কুকুরের লালাক্ষরণ হয়। তিনি প্রথমে একটি ঘন্টা বাজান এবং এরপর একটি কুকুরকে মাংস খেতে দেন। বেশ কয়েকবার এমন করার পর দেখলেন ঘন্টা দিয়ে মাংস না দিলেও কুকুরটির লালাক্ষরণ হচ্ছে। অর্থাৎ ঘন্টা দ্বারা লালাক্ষরণ নিয়ন্ত্রণ করা যাচ্ছে।
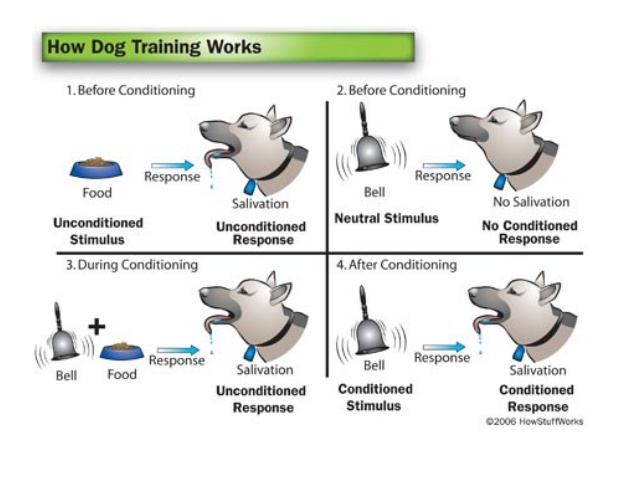
প্যাভলভের ক্লাসিক্যাল কন্ডিশনিং; source: SlideShare
তো কীভাবে ডগ স্কোয়াডে এর ব্যবহার হতে পারে? একটি হতে পারে কুকুরকে স্পটে নিয়ে যাওয়ার ক্ষেত্রে। অনেক কুকুরই যেতে চায় না বা অস্থিরতা প্রকাশ করে। সেগুলো নিয়মের মাঝে আনতে প্রতিদিন যেকোনো একটি স্পটে নিয়ে যেতে হবে এবং ফেরার পর খাবার দিতে হবে। এভাবে কিছুদিন করলে সে বুঝে যাবে যে, স্পটে গেলেই খাবার পাওয়া যায়। ধীরে ধীরে এটা রপ্ত হয়ে গেলে তখন খাবার না দিলেও পরের দিন যাবে। তবে দীর্ঘদিন বন্ধ থাকলে আচরণ আবার আগের মতো হয়ে যেতে পারে।

ট্রেনিং এ গুলির শব্দের সাথে পরিচিত করানো হচ্ছে; source: You Tube
স্কিনারের অপারেন্ট কন্ডিশনিং
উদ্দীপক পেলে সাড়া দেবে- এমনই এক মূল কথা মাথায় রেখে দেয়া হয় অপারেন্ট কন্ডিশনিং। যেমন ধরুন, একটি বাচ্চা পড়তে চাচ্ছে না। আপনি তাকে বললেন পড়লে চকোলেট পাবে- এই ক্ষেত্রেও ব্যাপারটি ঠিক তেমন। কুকুরদেরকে নির্দিষ্ট টাস্ক দেয়া হয়। যদি টাস্ক সম্পন্ন করতে পারে তবে পুরষ্কার পাবে, যদি না পারে তাহলে শাস্তি পাবে, যেমন- আঘাত করা, ধমকানো ইত্যাদি। তবে বিজ্ঞানীরা বলেন, শাস্তি দিয়ে ভালো কিছু আদায় করা সম্ভব নয়। তার চেয়ে কোনো টাস্ক না পারলে পুরস্কারটি না দেওয়াই তার জন্য শাস্তি হবে। এটিকে নেগেটিভ রি-ইনফোর্সমেন্ট বলা হয়। এই কন্ডিশনিংয়ের উদ্দেশ্য হলো ভালো আচরণকে পুরষ্কৃত করে সেই আচরণের পুনরাবৃত্তি ঘটানো।

source: Pinterest
স্কিনার আরো একটি পদ্ধতির কথা বলেছেন, তা হলো শেপিং। কোনো কঠিন একটি টাস্ককে ছোট ছোট অংশে ভাগ করে নেয়া এবং প্রতিটি অংশ সফলতার সাথে কমপ্লিট করার জন্য পুরষ্কৃত করাই হলো শেপিং। ডগ স্কোয়াড ট্রেনিংয়ে এ বিষয়টি প্রত্যেক ট্রেইনার মোটামুটি অনুসরণ করে থাকেন।
বান্দুরার সোশাল লার্নিং থিওরি
ছোট বাচ্চাদের সহজাত শিক্ষার প্রক্রিয়া খেয়াল করেছেন কি? তারা দেখে শেখে। অন্যরা কী করছে তা খেয়াল করে দেখে এবং তারপর তা নিজে করার চেষ্টা করে। অর্থাৎ খেয়াল করে দেখা এবং অনুকরণের সমন্বয়ই হলো আমাদের আচরণ। এই থিওরিকে সোশাল লার্নিং থিওরি বলে। আলবার্ট বান্দুরা এই বিষয়টি নিয়ে একটি পরীক্ষাও করেন।

ডগ ট্রেনিংয়ে সোশাল লার্নিং থিওরি এর ব্যবহার অনেকটা এমন; source: E-Learning-Provocateur
কুকুরের ট্রেনিংয়ের সময়ও এই থিওরি কিছুটা প্রয়োগ করা হয়। তবে বেশিরভাগ ক্ষেত্রেই ট্রেইনারকে অনুকরণের বদলে অভিজ্ঞ কুকুরকে মডেল হিসেবে অনুকরণ করানো হয়।
মাসলোর চাহিদা সোপান থিওরি
মাসলোর মতে, প্রতিটি প্রাণীর প্রয়োজনীয়তার একটি সোপান বা সিঁড়ি রয়েছে। এটি অনেকটা পিরামিড আকৃতির। প্রতিটি প্রাণীর ক্ষেত্রে এই সোপানের ব্যাখ্যা আলাদা আলাদা হলেও কিছু সাধারণ বৈশিষ্ট্য রয়েছে সকলের মাঝে, যেগুলো হলো মৌলিক চাহিদা, যেমন- খাদ্য, পানি, ভালোবাসা ইত্যাদি। অর্থাৎ ক্ষুধা, তৃষ্ণা এবং আনন্দ লাভ হলো প্রতিটি প্রাণীর প্রথম চাহিদা। আর এ কারণেই পোষা প্রাণীর আচরণ পরিবর্তনে পুরষ্কারের ব্যবস্থা করা হয়।
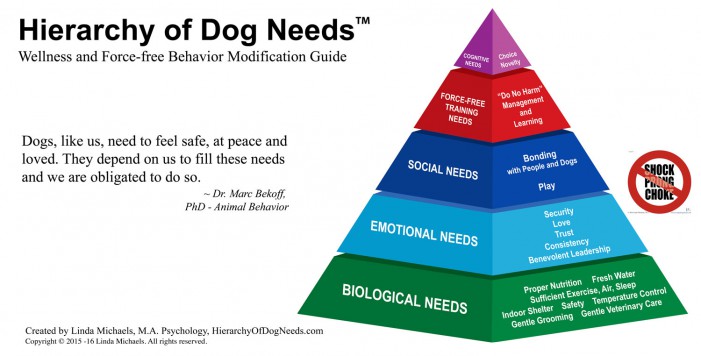
কুকুরের চাহিদা সোপান; source: thoseclevercanines.com
তাই ডগ ট্রেনিংয়ে কুকুরের ছোটখাটো একটি টাস্ক দেওয়া হয়। ভালো আচরণকে মৌলিক চাহিদা পূরণের মাধ্যমে পুরস্কৃত করা হয়। এতে করে কুকুরটি কাজে উৎসাহিত হবে এবং শান্ত হয়ে বসবে। এরপর আরেকটু হার্ড টাস্ক দেওয়া হবে এবং পারলে আবারো মৌলিক চাহিদার একটি পূরণ করা হয়। এতে করে কুকুরটি আনন্দিত হবে এবং পরবর্তী টাস্কগুলো সফলতার সাথে করার চেষ্টা করবে।

হার্ড টাস্ক ট্রেনিং দেয়া হচ্ছে ডগ স্কোয়াডকে; Source: BBC.com
টলম্যানের ল্যাটেন্ট লার্নিং
বারবার পুরস্কার না দিয়ে একটি নির্দিষ্ট সময় পরপর বা নির্দিষ্ট পরিমাণ টাস্ক কমপ্লিটের পর দিলে লার্নিংয়ের ফলাফল ভালো হয়। এই থিওরিটি টলম্যান ইঁদুরের উপর কাজ করে দিলেও, তা কুকুরের ক্ষেত্রেও প্রযোজ্য হবে।
ধরুন, কুকুরকে কোনো উঁচু পাঁচিল লাফিয়ে পার হওয়া শিখাতে হবে। তাহলে কুকুরকে চেষ্টা করতে দিন। অনেকবার চেষ্টার পর তাকে খাবার দিন পুরষ্কার হিসেবে। তাহলে দেখবেন পুরষ্কার পাবার পর খুব দ্রুত এবং সঠিকভাবে টাস্ক কমপ্লিট করতে পারছে। আর তাই এটিকে ল্যাটেন্ট লার্নিং বলে।

ট্রেনিংপ্রাপ্ত স্কোয়াড; source: news.mongabay.com
ডগ ট্রেনিংয়ে মাঝে মাঝেই কুকুরগুলোকে মানুষ এবং অন্যান্য কুকুরের সংস্পর্শে সামাজিক করার চেষ্টাও করা হয়, যেন স্পটে গিয়ে মানুষ বা অন্য পরিবেশ দেখে ভীত না হয়ে পড়ে। আর ডগ ট্রেনিং কখনো শেষ হবার নয়। অভিজ্ঞ কুকুরগুলোকেও নিয়মিত প্র্যাকটিস করাতে হয়। পরিশেষে, ডগ ট্রেনিংয়ে মনোবিজ্ঞানের এসব থিওরি ব্যবহৃত হয় খুবই দক্ষ হাতে। একজন অভিজ্ঞ ডগ ট্রেইনারের পক্ষেই তা সম্ভব।